
















Webseiten
Von Johannes Renz
")
Definition der Quellengattung
Eine Website (Webaufritt, Webpräsenz, Webangebot, umgangssprachlich Homepage) ist eine sich virtuell im Word Wide Web befindliche Ansammlung mehrerer Webseiten (Dateien), die durch den gemeinsamen Anteil einer Zeichenfolge (Domain) als zusammengehörig erkennbar und durch Hypertext-Verlinkung miteinander verbunden sind. Websites können auf einem oder mehreren Servern (Hosts) gespeichert sein. Von einer festgelegten Startseite aus, welche auch die Funktion eines Inhaltsverzeichnisses hat, kann über Hyperlinks fast beliebig auf verschiedene nachgeordnete Webseiten oder direkt auf andere Webauftritte navigiert (gesurft) werden. Dies macht Websites einerseits komfortabler als etwa handschriftliche oder gedruckte Quellen, andererseits aber auch unübersichtlicher. Von der analogen Welt her betrachtet sind Websites am ehesten mit Nachschlagewerken vergleichbar.
Websites sind sowohl Archiv- als auch Sammlungsgut. Da das Word Wide Web allgemein zugänglich ist, handelt es sich letztlich um Publikationen.
Historische Entwicklung
Das für uns heute selbstverständliche World Wide Web entstand im Jahr 1989/90.[1] und war zunächst nur für Spezialisten zugänglich. Maßgeblicher Entwickler und Begründer war Tim Berners-Lee, ein britischer Physiker, Informatiker, Erfinder der Hyper Text Markup Language (HTML) und Mitarbeiter des CERN in Genf. Ein Jahr später, am 13. November 1990, präsentierte er die weltweit erste Website. Es dauerte noch bis 1993, ehe der erste grafikfähige Internetbrowser entwickelt wurde. Im August desselben Jahres kam es zu Gründung des Deutschen Network Information Centers (DENIC).[2] Etwa 1996 begannen öffentliche Institutionen in Deutschland, sich zunehmend mit eigenen Internetauftritten zu präsentieren. Die DENIC konstituierte sich nun als Genossenschaft und erhielt 1997 ihren Geschäftssitz in Frankfurt am Main. Ein einschneidendes Datum war das Jahr 1998, in welchem Larry Page und Sergey Brin die Suchmaschine Google entwickelten und das gleichnamige Unternehmen Google Inc. gründeten.[3] Die 2001 von Jimmy Wales gegründete Online-Enzyklopädie Wikipedia erlangte als Mitmach-Projekt für jedermann rasch große Bedeutung und stellt als spendenfinanziertes Non-Profit-Projekt einen gewissen Gegenpol zum kommerziellen Riesen Google dar. Das Phänomen Wikipedia spielte auch eine beträchtliche Rolle bei der Entstehung des so genannten Web 2.0,[4] ein Begriff, der 2003 in der Zeitschrift CIO seine Ersterwähnung fand.[5] Die ersten Webpräsenzen waren sehr statisch und von geringem Umfang. Ihre Erstellung erforderte fortgeschrittene Programmierkenntnisse. Heute werden Webinhalte dynamisch generiert. Zahlreiche frei und kostenlos im Internet verfügbare Softwareanwendungen machen die Erstellung von Webseiten auch für Computerlaien mit vergleichsweise geringem Aufwand möglich.
Aufbau und Inhalt
Webseiten von Behörden, Unternehmen, Parteien, Verbänden und sonstigen Institutionen dienen vor allem der Öffentlichkeitsarbeit und dem Kontakt mit dem Bürger bzw. Kunden. Sie sind wichtige Aushängeschilder nach außen und dokumentieren das Selbstverständnis der jeweiligen Einrichtung. Ihre Struktur und Arbeitsweise wird komprimiert abgebildet. So werden etwa auch Organigramme und Geschäftsverteilungspläne erst durch das Aufkommen des Internets mit der Öffentlichkeit kommuniziert.
Neben der klassischen Homepage entstehen regelmäßig auch Sonderwebseiten, etwa für Image- und Werbekampagnen oder Informationsportale zu einem bestimmten gesellschaftlich relevanten Thema. Da Webseiten einer Impressumpflicht unterliegen, ist die Provenienz jeweils leicht feststellbar.
Webseiten bestehen aus einer großen Anzahl von Einzelseiten und sonstigen Dateien, die durch so genannte Links miteinander verbunden sind. Aufgrund der praktisch unbegrenzten Verlinkungsmöglichkeiten und der großen Anzahl an Dateitypen, die innerhalb von Webseiten verknüpft sind, zeichnen sich Webseiten im Vergleich zu analogem und oftmals auch anderem digitalen Archivgut durch eine äußerst komplexe Struktur aus. Neben Texten sind in Webseiten auch zahlreiche digitale Bilder und Videos, Tabellen, Datenbanken, Animationen und Präsentationen eingebunden. Mit Webseiten können nicht nur interne, sondern auch externe Daten verknüpft werden. Letztere gehen bei archivierten Webseiten i.d.R. verloren. Eine Volltextsuche ermöglicht eine vergleichsweise rationelle Recherche nach Schlagworten.
Überlieferungslage und ggf. vorarchivische/archivische Bearbeitungsschritte
Als erste Institution begann das Internet Archive USA in San Francisco im Jahre 1996 mit der systematischen Sicherung von Webseiten und ist auf dem Gebiet der Webarchivierung inzwischen weltweit aktiv. In Deutschland starteten erste Projekte zur Webarchivierung erst etwa 10 Jahre später, so dass das erste Jahrzehnt des deutschen Internets zumindest, was in Deutschland bestehende Server anbelangt, eine riesige Überlieferungslücke darstellt. Seitdem ist das Bewusstsein für die Wichtigkeit der Webarchivierung auch hierzulange gestiegen. Die Intensität, mit der einzelne Gedächtnisinstitutionen Webarchivierung betreiben, ist allerdings sehr unterschiedlich. Die Vorreiter sind eher im Bibliotheks- als im Archivbereich zu finden. Neben dem Bundes- und einzelnen Landesarchiven sind vor allem Hochschul-, Kommunal-, Wirtschafts-, Parlaments- und Parteiarchive teilweise in die Webarchivierung eingestiegen. Neben Behördenwebseiten finden sich in deutschen Webarchiven hauptsächlich Seiten von Landkreisen, Städten und Gemeinden, Parlamenten, politischen Parteien, Hochschulen und anderen wissenschaftlichen Institutionen. Nach wie vor sehr groß ist die Überlieferungslücke bei privaten Webseiten und Blogs, u.a. auch auf Grund der schwierigen (Urheber-) Rechtslage, die den Abschluss von sorgfältig ausformulierten Archivierungsverträgen zwingend notwendig macht, während die technischen Möglichkeiten grundsätzlich gegeben sind.
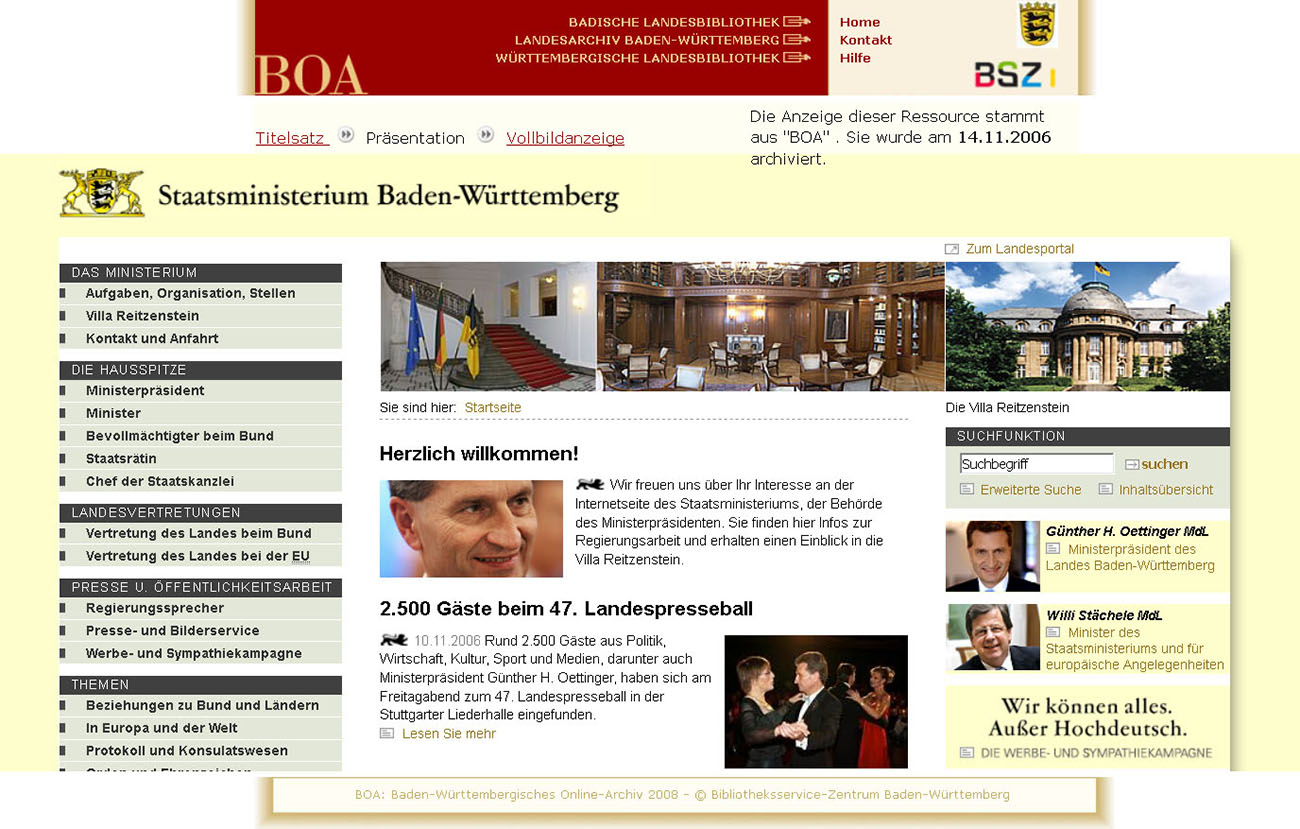
Webarchivierung ist eine Sonderform der digitalen Archivierung. Webseiten werden vom Archiv oder einer anderen Gedächtnisinstitution mit Hilfe eines Webcrawlers oder „Harvesters“ (z. B. HTTRACK oder Heritrix), einer Suchmaschine, mit deren Hilfe Webinhalte, die unter einer bestimmten Domain/URL liegen, heruntergeladen werden können, aktiv eingesammelt und auf einem Massenspeicher abgelegt. Falls die rechtlichen Voraussetzungen vorliegen, kann gleichzeitig auch die Nutzbarmachung mit Hilfe eines browserbasierten Viewers (z. B. Wayback Machine) erfolgen.
Die Sicherung („Harvesting“) von Webseiten erfordert vom Archivar gründliche Kenntnisse in der Informationstechnologie. Sinnvoll ist die Zusammenarbeit mit einem Dienstleister, der die notwendige Software bereitstellt und technische Unterstützung anbietet. Das Landesarchiv Baden-Württemberg arbeitet bei der Archivierung von Webseiten mit dem Bibliotheksservicezentrum Konstanz zusammen (BOA: Baden-Württembergisches Online-Archiv) und nutzt ein von diesem bereitgestelltes Softwarepaket. Die Feinkonfiguration des Webcrawlers wird für jede Webseite individuell durchgeführt. So kann etwa die herunterzuladende Speichermenge vorab festgelegt, bestimmte Inhalte einer Webseite ausgeschlossen oder auch Webinhalte außerhalb der zu sichernden Webseite hinzugefügt werden.
Nicht immer lassen sich Webseiten vollständig archivieren. Inhalte externer Plattformen wie z.B. Videos, die auf Youtube, Vimeo o.Ä. abgelegt sind, Bildergalerien, aber auch Datenbanken (sogenanntes Deep Web) und passwortgeschützte Inhalte („Interne Bereiche“) können i.d.R. nicht mit archiviert werden. Bei dynamisch generierten Webinhalten kann es nach wie vor zu Darstellungsproblemen oder anderen Fehlern kommen, da Webcrawler nicht immer rechtzeitig auf neue Entwicklungen im Webdesign reagieren können oder bei der Webseitenprogrammierung selbst bereits Fehler unterlaufen. Daher werden für Webseiten, die mit herkömmlichen Webcrawlern nicht geharvestet werden können, derzeit neue Lösungsansätze diskutiert. Große Unsicherheit herrscht immer noch in der Frage der Langzeitsicherung (preservation planning) von Webinhalten. Bislang beschränkt sich die Webarchivierung hauptsächlich auf die reine elektronische Speicherung entweder als Einzeldateien (u.a. HTTRACK) oder im Containerformat WARC (Heritrix).
Quellenkritik und Auswertungsmöglichkeiten
Grundsätzlich zählen Webseiten zu den subjektiven Quellen, da sie die Arbeit der eigenen Institution dokumentieren, und jeweils eine Innensicht dargestellt wird. Die weltanschauliche Neutralität von Webseiten hängt sehr stark von der Staatsnähe ab. Nicht nur staatliche und private Institutionen, auch politische Parteien, Kirchen und religiöse Organisationen, Verbände und sonstige Tendenzbetriebe stellen ihre Webseiten für eine Archivierung zur Verfügung oder betreiben teilweise selbst Webarchivierung.
Eine wesentliche Eigenschaft des Internets ist die ausgeprägte Flüchtigkeit von Webinhalten. In relativ kurzen Zeitabständen werden neue Inhalte generiert und alte entfernt. Die Archivierung von Webinhalten kann nur in bestimmten Zeitabständen erfolgen. Eine archivierte Webseite stellt daher stets eine Momentaufnahme von einem bestimmten Datum dar. Es besteht ständig die Gefahr, dass nur kurzzeitig online gestellte Inhalte nicht berücksichtigt werden. Gleichzeitig kann es zwischen den einzelnen Sicherungen („Snapshots“) auch zu großen Redundanzen kommen. Doch selbst wenn es möglich wäre, wäre es wenig sinnvoll, jede einzelne Änderung in eine einzige archivierte Version einer bestimmten Webseite einzupflegen, weil so ein Ist-Zustand suggeriert wird, den es im Live-Web niemals gegeben hat. Die Authentizität einer solchen Quelle würde nachhaltigen Schaden nehmen.
Webseiten lassen sich insbesondere für verwaltungs-, wirtschafts- und sozialgeschichtliche Zwecke auswerten. Die moderne Informations- und Dienstleistungsgesellschaft wird durch Webinhalte umfangreich dokumentiert. Im Zeitalter der vielzitierten „alternativen Fakten“ oder neudeutsch „Fake News“ ist eine quellenkritische und -vergleichende Herangehensweise für die Forschung unerlässlich.
Die Möglichkeit der Volltextsuche erhöht zwar grundsätzlich den Recherchekomfort, eine strukturelle Arbeitsweise vom Allgemeinen zum Besonderen im Stil eines „manuellen Crawlens“ ist beim quellenkundlichen Arbeiten mit einer Webseite allerdings äußerst schwierig. Die komplexe Linkstruktur lässt sich also nicht ohne weiteres in eine Linearstruktur bringen, wie man sie etwa in einer gedruckten Quelle findet.
Hinweise zur Benutzung
Die Nutzungsmöglichkeiten archivierter Webseiten hängen sehr stark von der jeweiligen Rechtslage ab. Webseiten sind zwar einerseits als Publikationen zu betrachten und unterliegen daher grundsätzlich keinen archivischen Sperrfristen. Daher können archivierte Webseiten staatlicher, kommunaler und sonstiger öffentlicher Einrichtungen direkt über das Internet für die Nutzung bereitgestellt werden. Auf der anderen Seite sind Webseiten von Privatpersonen und nichtöffentlichen Institutionen urheberrechtlich geschützt. Diese können daher nur dann online bereitgestellt werden, wenn keine urheberrechtlichen Aspekte entgegenstehen und dies im Vorfeld der Archivierung durch Verträge mit Webseitenbetreibern bzw. Domaininhabern sichergestellt wurde. Bei unsicherer Rechtslage sollten Webseiten auf einer nicht öffentlich zugänglichen Plattform, z.B. dem Digitalen Magazin des Landesarchivs (DIMAG) abgelegt und können ggf. erst nach einer entsprechenden Sperrfrist – grundsätzlich wären dies 75 Jahre nach Tod des (jüngsten) Urhebers – öffentlich zugänglich gemacht werden.
Archivierte Webseiten besitzen eine Archiv-URL (uniform resource locator) und/oder eine URN (uniform resource name), nach der sie zitiert werden können. Zusätzlich sollte das Datum des Snapshots angegeben werden. Bei der Zitierung nicht archivierter Webseiten wird neben der URL auch das Datum des Seitenaufrufs genannt.
Forschungs- und Editionsgeschichte
Webseiten sind ein in die Gegenwart reichendes zeitgeschichtliches Phänomen, das im Grunde seit seinem Bestehen kontinuierlich erforscht wird. Die Erforschung des Internets wird zumindest nicht federführend von klassischen Historikern betrieben, sondern hauptsächlich von Forschern, die sich mit Gegenwartsphänomenen beschäftigen, etwa Sozialwissenschaftlern oder Politologen. Archivierte Webseiten sind oftmals noch zu junge Quellen, um stärker im Fokus historischer Forschung zu stehen. Zudem halten datenschutzrechtliche Hürden möglicherweise längerfristig von historischen Forschungsvorhaben ab.
Anmerkungen
[1] Cailliau, History.[2] https://www.denic.de/ueber-denic/denic-geschichte (14.06.2017). Das Kürzel „.de“ für eine Domain aus Deutschland wurde allerdings bereits 1986 festgelegt.
[3] https://www.google.de/about/our-story/ (aufgerufen am 14.06.2017).
[4] http://wirtschaftslexikon.gabler.de/Definition/web-2-0.html (aufgerufen am 14.06.2017).
[5] https://books.google.de/books?id=1QwAAAAAMBAJ&printsec=frontcover&source=gbs_summary_r&redir_esc=y#v=onepage&q&f=false (14.06.2017).
Literatur
- AWV-Informationen Spezial: Webarchivierung (kostenlos bestellbar bei der Arbeitsgemeinschaft für wirtschaftliche Verwaltung: http://www.awv-net.de/cms/index-b-138-790.html).
- Brown, Adrian, Archiving Websites: A Practical Guide for Information Management Professionals, London 2006.
- Bunz, Mercedes, Vom Speicher zum Verteiler. Die Geschichte des Internet, Berlin 2008.
- Cailliau, Robert, A Little History of the World Wide Web, CERN/W3C, 1995 (https://www.w3.org/History.html, 14.06.2017).
- Die Geschichte des Internets: https://www.lmz-bw.de/geschichte-internet.html (04.05.2017).
- Masanès, Julien, Web Archiving, Berlin/Heidelberg 2010.
- Naumann, Kai, Ungelöstes Problem oder ignorierte Aufgabe? Web-Archivierung aus der Sicht deutschsprachiger Archive, Vortrag auf der 14. Tagung des Arbeitskreises „Archivierung von Unterlagen aus digitalen Systemen“ bei der Generaldirektion der Staatlichen Archive Bayerns am 1. März 2010, online: https://www.landesarchiv-bw.de/web/52457 (14.06.2017).
- Naumann, Kai, Gemeinsam stark – Web-Archivierung in Baden-Württemberg, Deutschland und der Welt, in: Archivar. Zeitschrift für Archivwesen 1 (2012), S. 33–41.
- Steinhauer, Eric W., Rechtliche Fragestellungen rund um die Webarchivierung (files.dnb.de/nestor/veranstaltungen/2012-03-20/4.1_steinhauer.pdf, 04.05.2017), Textfassung (zusammen mit Ellen Euler) in: Informationen der Arbeitsgemeinschaft für wirtschaftliche Verwaltung e. V., Spezialheft Webarchivierung, Eschborn 2012, S. 30–33.
- Teske, Frank, Archivierung des Internets – eine Aufgabe für Archive?, Stuttgart/Marburg 2003 (https://www.landesarchiv-bw.de/sixcms/media.php/120/47191/transf_teske_internet.pdf (04.05.2017).
Zitierhinweis: Johannes Renz, Webseiten, in: Südwestdeutsche Archivalienkunde, URL: […], Stand: 14.06.2017.
Teilen
 leobw
leobw